ادامه طبقهبندی …
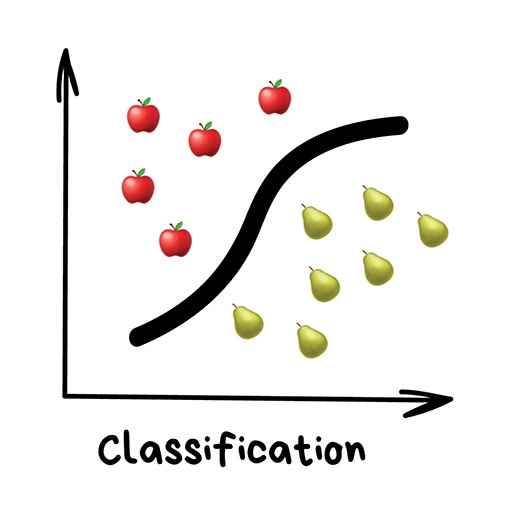
بیایید نمونهی عملی دیگری از طبقهبندی را با هم بررسی کنیم. فرض کنید شما میخواهید مبلغی از بانک وام یا اعتبار بگیرید. چگونه بانک تشخیص میدهد که شما وام را بازپرداخت خواهید کرد یا نه؟ قطعا هيچ راهی برای کسب اطمینان صد در صدی وجود ندارد. اما بانک پرونده تعداد زیادی از مشتریان را دارد که قبلا وام گرفتهاند. بانک اطلاعات مربوط به سن، تحصیلات، شغل و حقوق و مهمتر از همه اینکه وام را بازپرداخت کردهاند یا خیر را دارد.
با استفاده از این دادهها میتوانیم روش یافتن الگوها (pattern) و پیدا کردن پاسخ این سوال را به ماشین آموزش دهیم. در اینجا مشکل خاصی برای پیدا کردن پاسخ وجود ندارد. موضوع اصلی این است که بانک نمیتواند کورکورانه به پاسخ ماشین اعتماد کند. زیرا ممکن است خرابی سیستم (system failure) یا حمله هکرها اتفاق افتاده باشد یا حتی ممکن است کارمند سالخوردهای که در وضعیت سرخوشی (drunk) است با راهکار سریعاش برای رفع خطا (quick fix) باعث خرابی سیستم شده باشد.
برای حل این گونه مسائل از درخت تصمیم (Decision Tree) استفاده میشود (اینجا را هم ببیند https://bit.ly/3PZNLRl ).
تمام دادهها به صورت خودکار به سوالات بله/خیر تقسیم میشوند برای مثال «آیا درآمد وامگیرنده بیش از ۱۲۸.۱۲ دلار است؟». چنین کاری میتواند از نگاه انسانها کمی عجیب به نظر برسد. با این حال، ماشین چنین سوالاتی را مطرح میکند تا دادهها را در هر گام به بهترین شکل تقسیم کند.
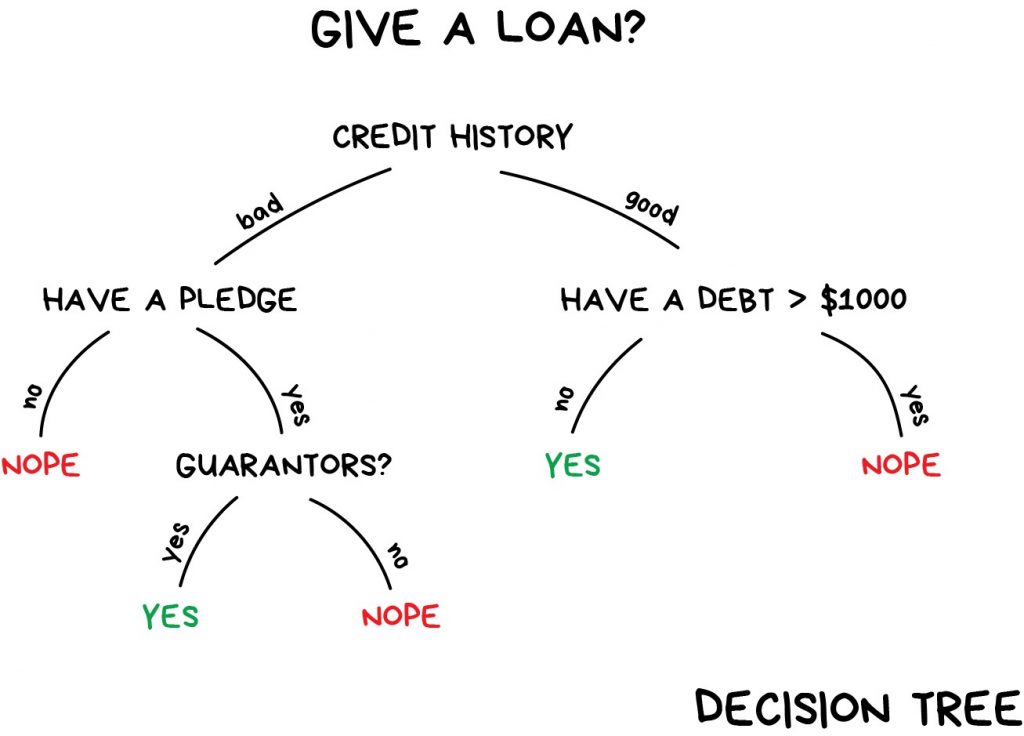
با این روش، درخت تصمیم ساخته میشود. هرچه ارتفاع درخت بیشتر باشد (مترجم؛ به شکل نگاه کنید) به این معناست که سوالها گستردهتر هستند. هر تحلیلگری میتواند درخت را ببیند و آن را توضیح دهد. ممکن است منطق آن را درک نکند اما به راحتی میتواند آن را توضیح دهد! (منظور من تحلیلگرهای معمولیاند)
درخت تصمیم به طور گستردهای در حوزههای پرمسئولیتی مانند تشخیص بیماری، پزشکی و امور مالی استفاده میشوند.
امروزه به ندرت از درخت تصمیم به تنهایی و بدون ترکیب با سایر تکنیکها استفاده میشود. با این حال، آنها معمولا پایه و اساس سیستمهای بزرگ را تشکیل میدهند و ترکیب گروهی از آنها حتی بهتر از شبکههای عصبی کار میکند. بعداً در این مورد صحبت خواهیم کرد.
وقتی عبارتی را در گوگل جستجو میکنید دقیقا گروهی درخت تصمیم وجود دارند که دنبال طیف وسیعی از پاسخها میگردند. موتورهای جستجو به دلیل سرعت بالا، عاشق درختهای تصمیم هستند.
دو مورد از الگوریتمهای معروف برای ساختن درخت CART و C4.5 هستند.
مترجم: خانم سپیده مشایخی
گزیده:
من به تازگی از توماسو پوجیو، یکی از پیشگامان علم عصبشناسی مدرن، پرسیدم که آیا نگران نیست که رایانهها با قدرت پردازشی فزایندهای که دارند به زودی بتوانند به تقلید از کارکرد مغز انسان بپردازند؟ او پاسخ داد: هیچ بختی ندارند.
ست لوید (Seth Lloyd)
منبع: کتاب تراوشهای ذهنی، ۲۵ شیوه نگرش به هوش مصنوعی