ادامه طبقهبندی …
ماشین بردار پشتیبان (Support Vector Machines) یا SVM به راستی محبوبترین روش طبقهبندی کلاسیک است. از آن برای طبقهبندی هر موجودی در جهان هستی استفاده میشود مانند طبقهبندی گیاهان بر اساس شکل ظاهری آنها در عکس یا طبقهبندی اسناد بر اساس نوع آنها و…
ایدهی پشت SVM بسیار ساده است. SVM سعی میکند تا دو خط با بیشترین فاصلهی ممکن بین نقاط داده (data points) ترسیم کند. به تصویر زیر نگاه کنید.
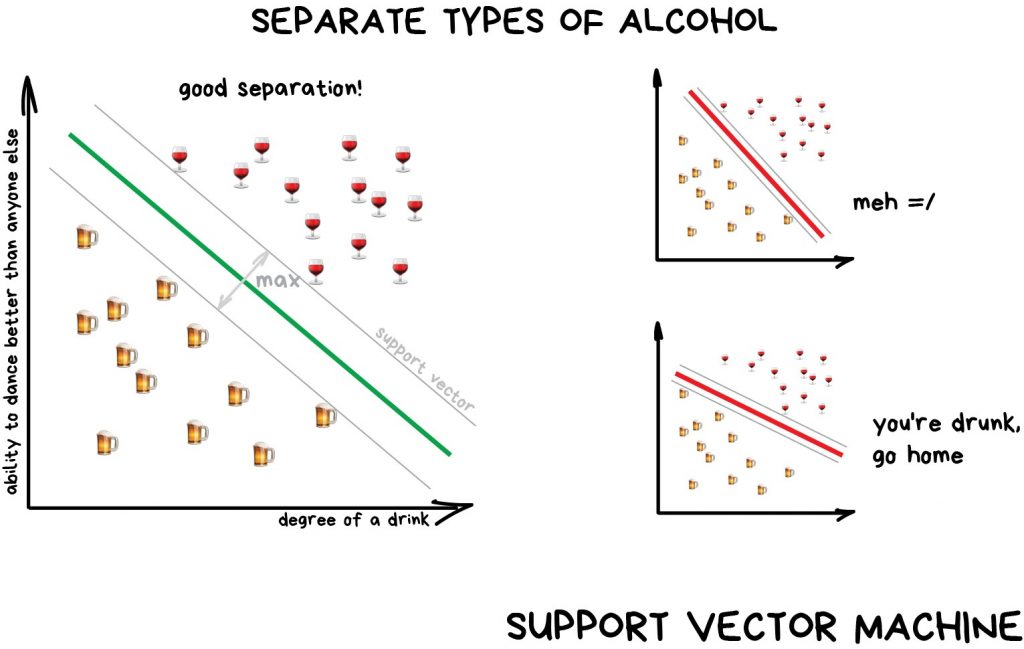
یکی از کاربردهای جنبی و بسیار مفید طبقهبندی، تشخیص ناهنجاری (anomaly detection) است. هنگامی که یکی از ویژگیهای داده در هیچ یک از طبقهها قرار نمیگیرد(مترجم؛ مثلا در دستهبندی عکسها به عکس سگ و عکس گربه، عکسی از فیل وجود داشته باشد)، آن را برجسته و اعلام میکنیم. این روزها از تشخیص ناهنجاری در پزشکی و برای تصاویر MRI استفاده میشود. رایانهها تمام مناطق مشکوک به بیماری یا متفاوت با حالت عادی آزمایش را برجسته و گزارش میکنند. بازارهای سهام از این تکنیک برای شناسایی رفتار غیرعادی معاملهگران و پیدا کردن معاملهگرانی که به صورت غیرقانونی به اطلاعات محرمانهی شرکتها دسترسی دارند استفاده میکنند. در اینجا، وقتی میخواهیم دادههای درست را به کامپیوتر آموزش بدهیم در واقع دادههایی را به آن آموزش میدهیم که در واقع اشتباه و نادرستاند (مترجم؛ ما تصاویر پزشکی با علائم غیرعادی و مشکوک به بیماری و همچنین اطلاعات معاملهگران قانونگریز را به ماشین یاد میدهیم تا آنها را شناسایی کند).
امروزه معمولا برای طبقهبندی، بیشتر از شبکههای عصبی (neural networks) استفاده میشود. در حقیقت شبکههای عصبی اصلا برای همین کار به وجود آمدهاند.
قاعده کلی (rule of thumb) این است: هر چه دادهها پیچیدهتر، الگوریتم هم پیچیدهتر. برای دادههای متنی، عددی و جدولی، من روشهای کلاسیک را انتخاب میکنم. زیرا در روشهای کلاسیک، مدلها کوچکترند و سریعتر یاد میگیرند و البته عملکرد آنها شفافتر و قابلفهمتر است. برای تصاویر ، فیلم و بقیه کلان دادههای (big data) پیچیده، من قطعاً شبکههای عصبی را انتخاب میکنم.
تا پنج سال پیش هم میشد یک طبقهبندیکننده (classifier) برای دستهبندی چهرههای انسان پیدا کرد که با SVM ساخته شده باشد. اما امروزه برای انجام چنین کاری، راه آسانتر این است که از بین صدها شبکهی عصبی که از پیش آموزش دیدهاند (pre-trained) یکی را انتخاب کنید. اما روشهای بهکار رفته در فیلترکنندههای هرزنامهها (spam filters) هیچ تغییری نکردهاند و کماکان با SVM نوشته میشوند. و تاکنون هیچ دلیل منطقی و مناسبی برای تغییر آنها پیدا نشده است.
حتی وب سایت شخصی من نیز برای شناسایی هرزنامهها در بخش نظرات (comeents) از SVM استفاده میکند. ¯_(ツ)_/¯
مترجم: خانم سپیده مشایخی
گزیده:
از دید من، یادگیری ماشین ابزاری است برای رساندن ما از دادهها به احتمالات. اما برای رسیدن از احتمالات به درک واقعی، هنوز دو گام دیگر باید برداشته شود- دو گام بزرگ و مهم. یکی پیشبینی اثر اقدامات و دیگری تصور خلاف وابع
جودیا پرل (Judea Pearl)
منبع: کتاب تراوشهای ذهنی، ۲۵ شیوه نگرش به هوش مصنوعی